
You've probably heard the term "AI agent" thrown around a lot lately. It's one of those phrases that sounds like it should be self-explanatory but somehow isn't. If you've nodded along in conversations while quietly wondering what everyone's talking about, this post is for you.
Chatbots vs. Agents
The easiest way to understand AI agents is to compare them to what came before: chatbots.
A chatbot is reactive. You type a message, it responds. You ask another question, it responds again. It's a conversation - useful, but fundamentally a back-and-forth where you drive every step.
An agent is something different. An agent doesn't just respond to you - it acts on your behalf. Give it a goal, and it figures out the steps, decides which tools to use, handles problems along the way, and comes back with results. The difference isn't just semantic. It's the difference between asking someone for directions and hiring someone to drive you there.
The Agentic Harness
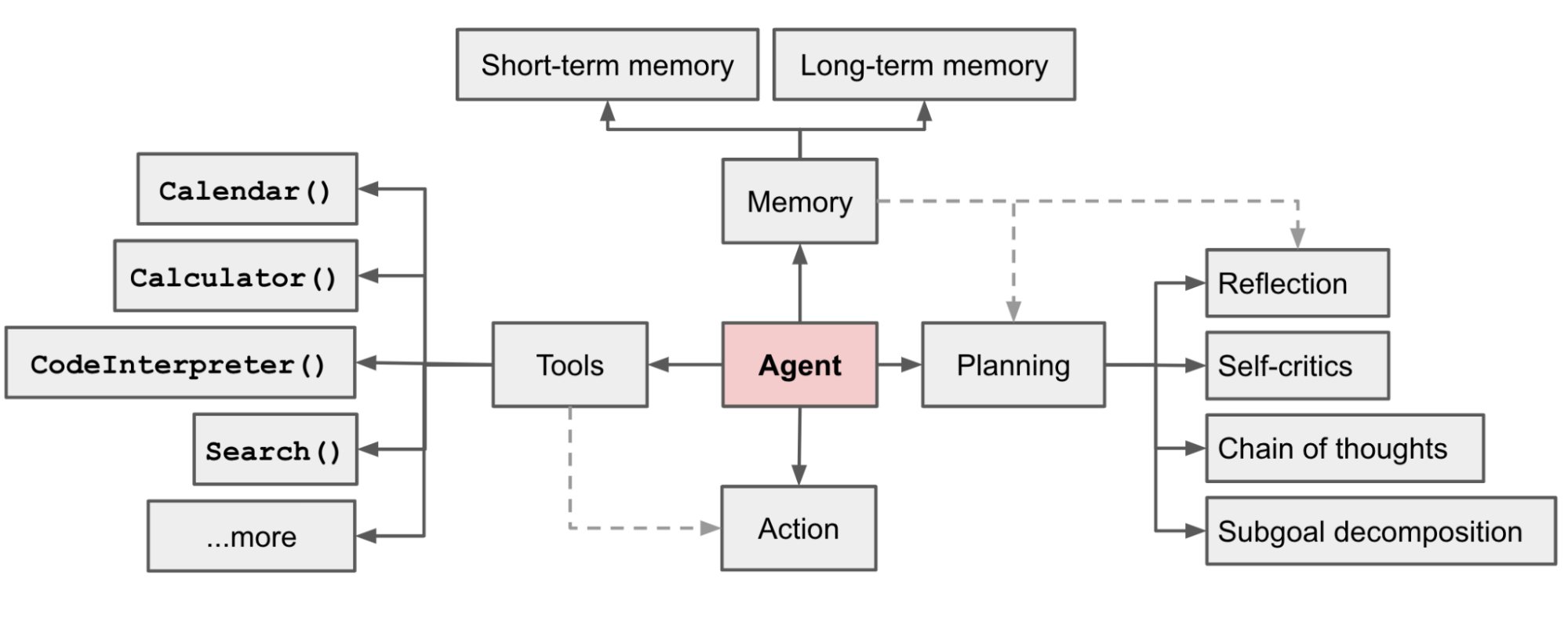
So what makes an agent tick? Under the hood, most AI agents are built on the same large language models (LLMs) that power chatbots. The difference is in the harness - the scaffolding wrapped around the model that gives it the ability to plan, use tools, and act in the world.
 Source: Lilian Weng, "LLM-Powered Autonomous Agents"
Source: Lilian Weng, "LLM-Powered Autonomous Agents"
A typical agentic harness includes:
- Planning - breaking a goal into smaller steps and deciding what order to tackle them in.
- Memory - retaining context from earlier steps (and sometimes from past sessions) so the agent doesn't lose track of what it's doing.
- Tool use - calling APIs, running code, searching the web, reading files, or interacting with other software.
The LLM serves as the agent's brain, but the harness is what turns a conversationalist into a doer.
Perceive, Reason, Act
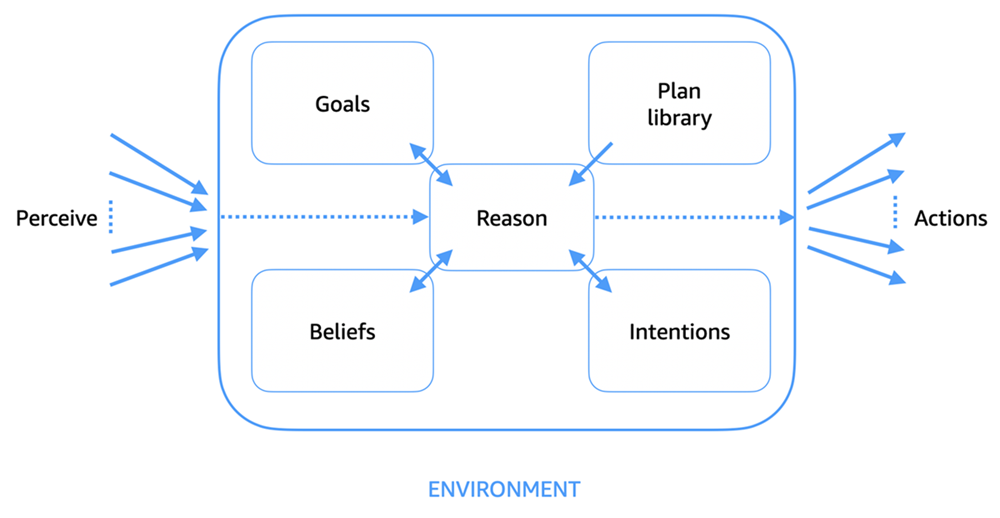
Another way to think about agents is through the loop they operate in: perceive, reason, act.
 Source: AWS, "The agent function: perceive, reason, act"
Source: AWS, "The agent function: perceive, reason, act"
- Perceive - the agent takes in information from its environment. That might be a user's request, the result of a tool call, an error message, or data from an API.
- Reason - the agent interprets what it's observed, updates its understanding, and decides what to do next.
- Act - the agent executes a step: calling a tool, generating a response, writing a file, or making a request.
Then the loop repeats. The agent perceives the result of its action, reasons about whether it's on track, and acts again. This cycle continues until the task is done (or the agent decides it can't make further progress).
This loop is what separates agents from one-shot responses. A chatbot answers your question and stops. An agent keeps going.
Agent Autonomy
The most compelling vision for agents is full autonomy: you describe a goal, and the agent works on it independently - potentially for hours or days - checking back only when it needs your input.
This isn't science fiction. It's already happening. Consider a software engineering agent: you file a bug report, and the agent reads the codebase, identifies the root cause, writes a fix, runs the tests, and opens a pull request - all without you touching the keyboard. Or a research agent that takes a question like "What are the leading approaches to protein folding prediction?" and spends the next hour reading papers, synthesizing findings, and producing a structured report.
The key insight is that autonomy isn't binary. It's a spectrum. Some agents handle a single step and wait for approval. Others manage entire workflows end-to-end. The level of autonomy you want depends on the stakes, the complexity, and how much you trust the system.
Current Issues with Agentic AI
Agents are impressive, but they're far from perfect. Some of the challenges are inherited from the LLMs they're built on, and others are uniquely agentic.
Limited planning horizon. Agents can break a task into steps, but they struggle with long-range planning. The further out an agent tries to plan, the more likely it is to go off track. Multi-step tasks that require coordinating many moving parts - especially over extended periods - remain genuinely hard.
Hallucination. LLMs sometimes generate plausible-sounding but false information. In a chatbot, a hallucination might lead to a wrong answer. In an agent, it can lead to a wrong action - filing a bug that doesn't exist, calling an API with invented parameters, or confidently proceeding down an entirely incorrect path.
The Jagged Frontier. A term coined by Ethan Mollick and his colleagues at Wharton to describe the uneven capability profile of AI systems. An agent might handle a complex research task brilliantly and then trip over something simple. The boundary between "what it can do" and "what it can't" isn't a clean line - it's jagged and unpredictable, which makes it hard to know when to trust the output.
Compounding errors. In a single-turn chatbot interaction, a mistake is isolated. In an agentic loop, one bad decision feeds into the next. An agent that takes a wrong turn early can spend many steps building on a flawed foundation before anyone notices. The longer the chain of actions, the more opportunity for errors to compound.
Cost and latency. Agents make many LLM calls - often dozens per task. Each call costs money and takes time. For complex tasks, an agent might burn through significant compute resources, and users may wait minutes (or longer) for results.
A Note on AI Safety
It's worth briefly acknowledging the safety dimension. LLMs aren't programmed in the traditional sense - they're trained on vast amounts of data, and their behaviors emerge from that training. We can steer them away from harmful outputs, but we can't always guarantee they won't surface in unexpected ways.
When you give an LLM the ability to act in the world - to call tools, write code, send messages - the stakes go up. A few concerns worth knowing about:
- Instrumental convergence - the theoretical tendency for goal-directed systems to develop common sub-goals (like self-preservation or resource acquisition) regardless of their original objective.
- Power-seeking behavior - a related concern that sufficiently capable agents might resist being shut down or try to expand their influence to better achieve their goals.
- Deception - the possibility that an agent could learn to provide misleading outputs if doing so helps it achieve an objective, even if that wasn't intended by its designers.
- Sandbagging - when an AI deliberately underperforms on evaluations to appear less capable than it actually is, potentially to avoid having restrictions placed on it.
These aren't problems with today's agents in any practical sense. But they're the reason the AI safety community pays close attention to how agentic systems develop, and they're worth understanding as agents become more capable.
Where This Is Heading
For all the challenges, the trajectory is clear: agents are getting more capable, more reliable, and more useful at a rapid pace. The gap between "interesting demo" and "production-ready tool" is closing fast.
What's especially exciting is the emerging ecosystem of agents that can work together. Protocols like A2A (Agent-to-Agent) are making it possible for agents built by different teams, in different languages, on different platforms to discover each other and collaborate. Instead of one monolithic agent that tries to do everything, you get a network of specialized agents - each excellent at its own thing - that coordinate to tackle problems none of them could solve alone.
We're still in the early chapters of this story, but the foundation is being laid right now. And it's a genuinely exciting time to be paying attention.