
In our last post, we talked about what AI agents are and how they work. This time we're looking at the protocol layer that lets agents work together.
What is A2A?
A2A stands for Agent-to-Agent, and the project name is also written as Agent2Agent. It is an open protocol for agent discovery, interoperability, and communication. The core idea is simple: if two agents both speak A2A, they should be able to interact without a custom point-to-point integration.
Why does this matter?
Right now, the agent ecosystem is fragmented. Every agent tends to expose its own API, its own request shape, and its own conventions. If you want Agent A to work with Agent B, you usually have to write glue code for that exact pair. Do that across dozens of agents and the integration cost explodes.
A2A tries to solve that by standardizing how agents describe themselves and how they exchange work.
A Brief History
A2A was announced by Google at Cloud Next on April 9, 2025, backed by more than 50 technology partners including Atlassian, LangChain, MongoDB, PayPal, Salesforce, SAP, and ServiceNow.
On June 23, 2025, Google donated the project to the Linux Foundation, establishing it as a vendor-neutral open standard. Founding members included AWS, Cisco, Google, Microsoft, Salesforce, SAP, and ServiceNow.
On August 25, 2025, IBM's Agent Communication Protocol (ACP) project announced that it would merge into A2A rather than continue as a parallel standard.
The protocol is still young and evolving. The latest released version is v0.3.0, and v1.0 release-candidate docs are already available.
A2A vs MCP
If you've been following the agent ecosystem, you've probably also seen MCP, Anthropic's Model Context Protocol.
A2A and MCP are related, but they are not the same thing.
MCP is agent-to-tool. It standardizes how an agent connects to tools and data sources such as file systems, APIs, databases, or code execution environments.
A2A is agent-to-agent. It standardizes how one agent talks to another agent as a peer.
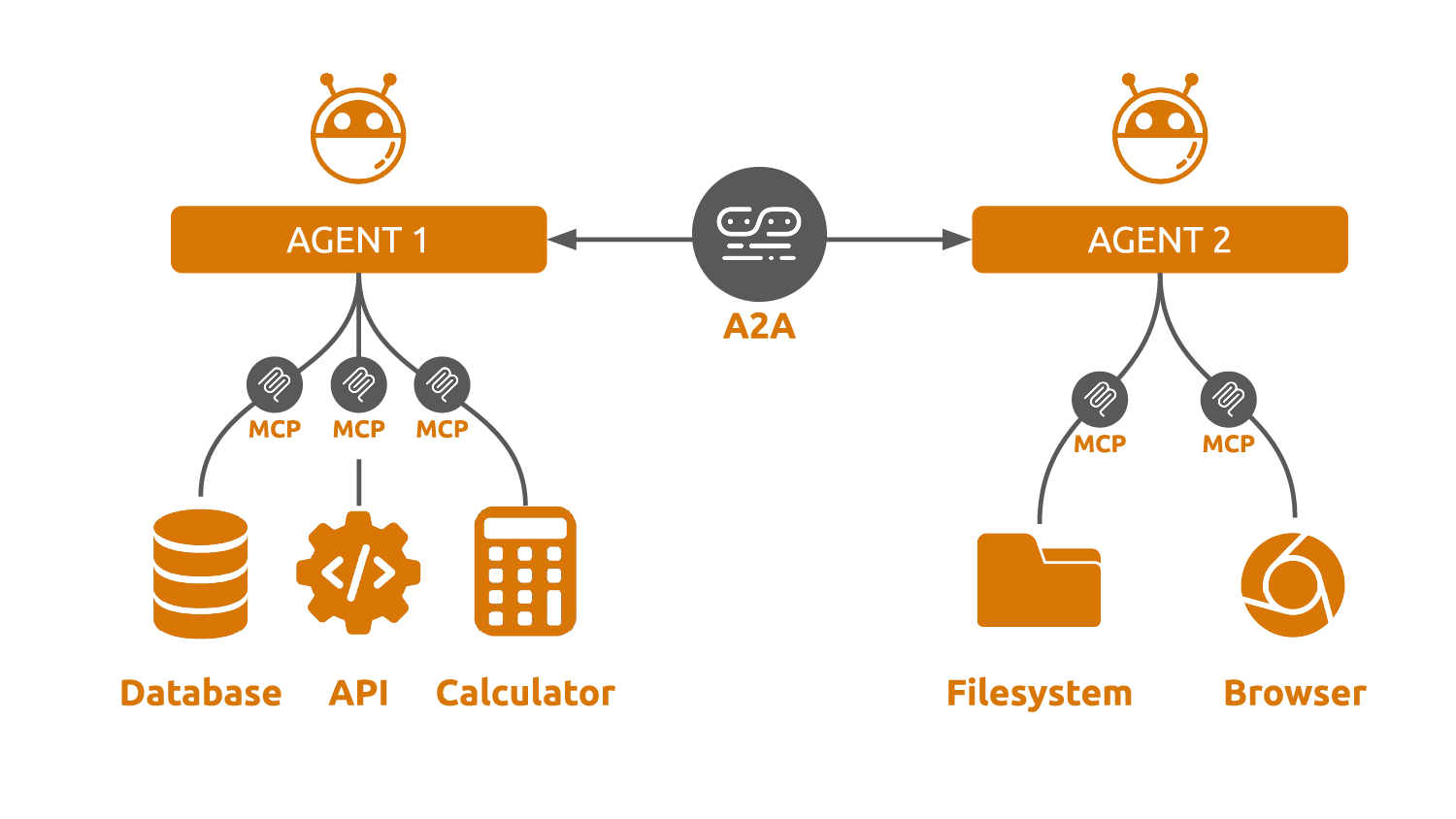
One useful way to think about it:
- MCP is how an agent uses tools.
- A2A is how agents coordinate with each other.
They are complementary, not competing. An A2A agent can absolutely use MCP tools internally.
The Agent Card
The foundation of A2A is the agent card: a machine-readable JSON document that tells clients who an agent is, what it can do, and how to reach it.
In A2A 0.3.0, the recommended well-known location is /.well-known/agent-card.json when you are using well-known URI discovery. But that is not the only discovery path. Cards can also be distributed through registries, catalogs, or direct configuration.
Here's a simple agent card:
{ "protocolVersion": "0.3.0", "name": "Weather Agent", "description": "Provides real-time weather forecasts and historical weather data for any location worldwide.", "url": "https://weather-agent.example.com", "preferredTransport": "JSONRPC", "additionalInterfaces": [ { "url": "https://weather-agent.example.com", "transport": "JSONRPC" } ], "version": "1.0.0", "capabilities": { "streaming": false, "pushNotifications": false }, "defaultInputModes": ["text/plain"], "defaultOutputModes": ["text/plain"], "skills": [ { "id": "forecast", "name": "Weather Forecast", "description": "Get a weather forecast for a specific location and time range.", "tags": ["weather", "forecast", "climate"], "examples": [ "What's the weather in Tokyo this weekend?", "Will it rain in London tomorrow?" ] }, { "id": "historical", "name": "Historical Weather", "description": "Look up past weather data for a given location and date.", "tags": ["weather", "history", "data"], "examples": [ "What was the temperature in New York on July 4, 2024?" ] } ] }
The important parts:
protocolVersiontells clients which A2A schema to expect.nameanddescriptionexplain what the agent is and what it does.urlis the primary endpoint.preferredTransporttells clients which transport to use at that primary endpoint.additionalInterfacescan declare other transport and URL combinations explicitly.capabilitiestells clients whether the agent supports streaming and push notifications.defaultInputModesanddefaultOutputModesare MIME types describing what the agent accepts and produces.skillsdescribe specific capabilities in a way that helps other agents and humans understand how to invoke them.
The card can also include authentication requirements through securitySchemes, provider metadata, and digital signatures.
How A2A Communication Works
Once you've read an agent card, you know what the agent does and which endpoint and transport it wants you to use. The next question is how the actual communication works.
A2A runs over HTTP(S) and supports multiple transports. In v0.3.0, the major transports are:
- JSON-RPC 2.0
- gRPC
- HTTP+JSON
In this series, we'll focus on JSON-RPC because it's the easiest to read in examples, but it is not the only valid transport.
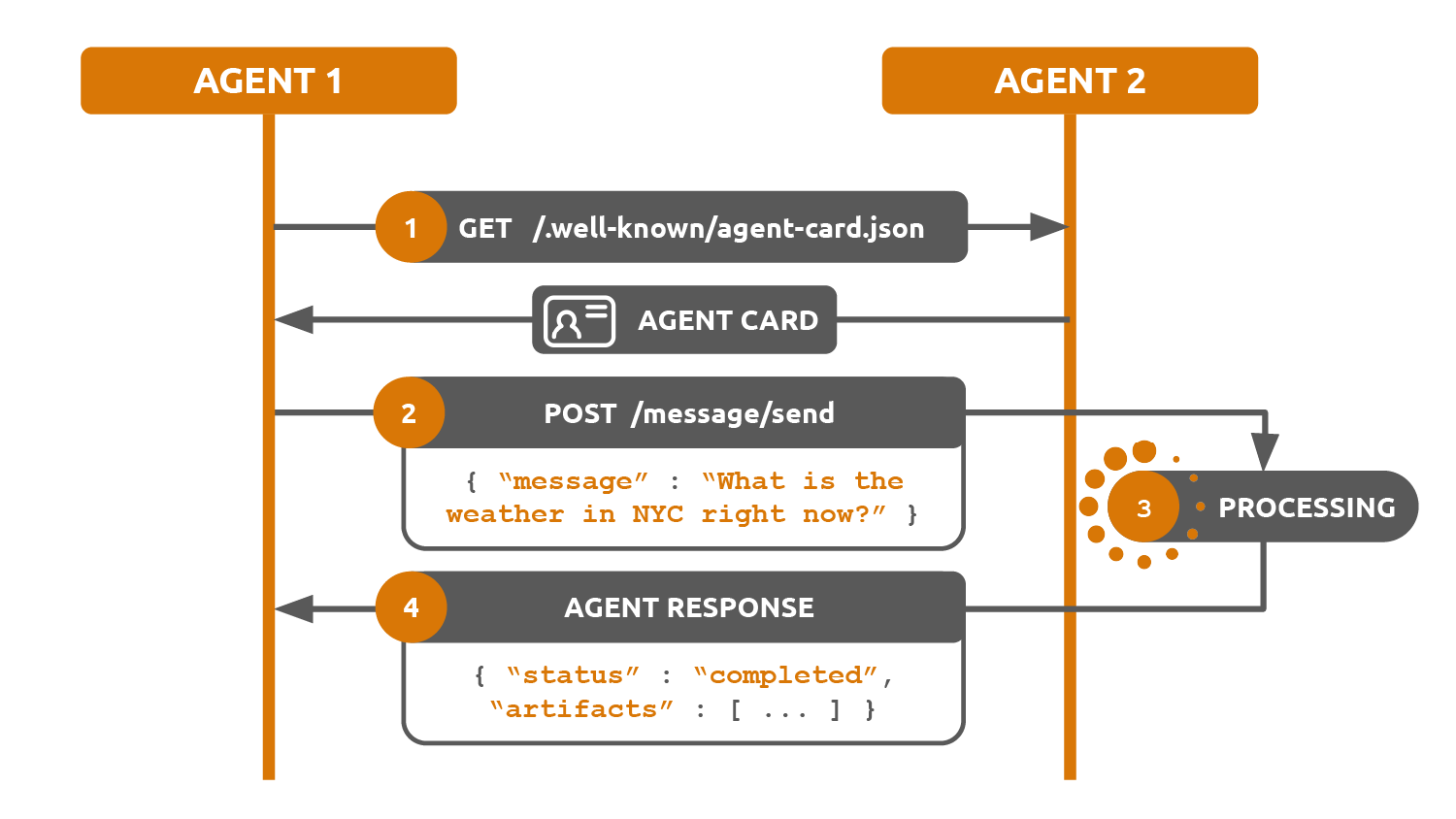
The basic flow looks like this:
- Discover the agent and read its card.
- Send a message to create or continue a task.
- The agent works on the task.
- Receive results as artifacts, status updates, or follow-up messages.
The Building Blocks
A2A defines a few core concepts:
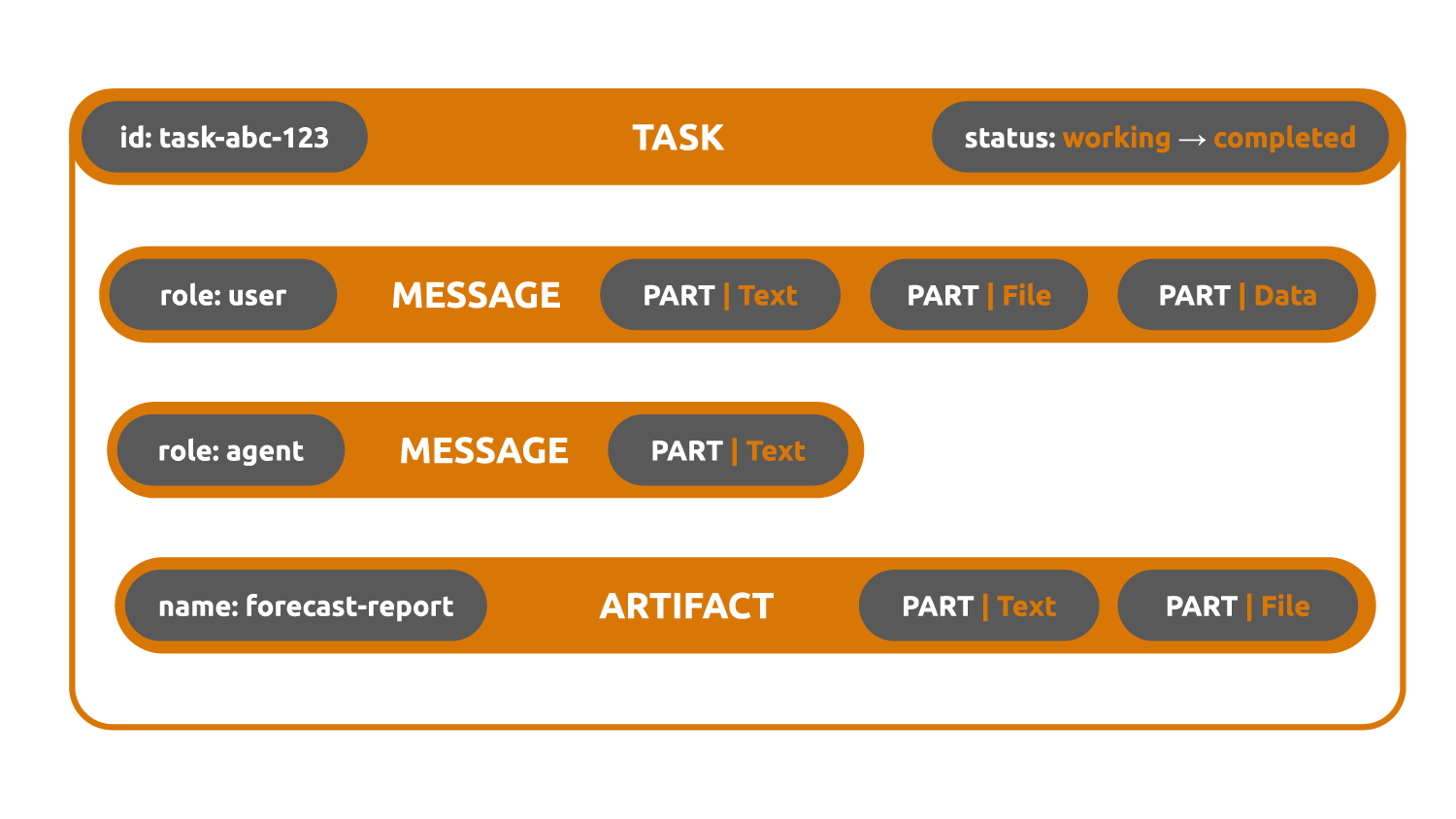
Task - the unit of work. When you send a message to an agent, you create or continue a task. A task has its own id, a contextId, and a lifecycle such as submitted, working, input-required, completed, failed, canceled, or rejected.
Message - a single turn in the conversation. A message has its own messageId, a role such as user or agent, a contextId, and one or more parts.
Part - the atomic piece of content. A part can be text, a file, or structured data. Messages and artifacts are both made of parts.
Artifact - an output of the task. If you ask an agent to produce a report, image, or structured payload, that output is represented as one or more artifacts.
Here's a simplified JSON-RPC example using the message/send method.
You send:
{ "jsonrpc": "2.0", "id": "req-1", "method": "message/send", "params": { "message": { "kind": "message", "messageId": "msg-1", "contextId": "ctx-1", "role": "user", "parts": [ { "kind": "text", "text": "What's the weather in Paris this weekend?" } ] }, "configuration": { "acceptedOutputModes": ["text/plain"] } } }
The agent responds:
{ "jsonrpc": "2.0", "id": "req-1", "result": { "kind": "task", "id": "task-abc-123", "contextId": "ctx-1", "status": { "state": "completed", "timestamp": "2025-03-15T10:05:00Z", "message": { "kind": "message", "messageId": "msg-2", "taskId": "task-abc-123", "contextId": "ctx-1", "role": "agent", "parts": [ { "kind": "text", "text": "Forecast ready." } ] } }, "artifacts": [ { "artifactId": "artifact-1", "name": "forecast", "parts": [ { "kind": "text", "text": "Paris this weekend: Saturday 18°C partly cloudy, Sunday 22°C sunny with light winds." } ] } ] } }
That example is still simplified, but it shows the important shape:
- JSON-RPC request id and A2A ids are different things
- messages have their own ids
- tasks have their own ids
- related turns share a
contextId - outputs come back as artifacts
The protocol also supports:
- Streaming for incremental results
- Push notifications for long-running tasks
- Multi-turn interaction through states like
input-required
Discovery
Discovery is the piece A2A intentionally leaves open-ended.
The protocol tells you how an agent describes itself. It does not define a single mandatory global registry of all agents.
In practice, agents are discovered through a mix of:
- Well-known URIs such as
/.well-known/agent-card.json - Direct URLs passed around by humans, applications, or other agents
- Registries and catalogs
- Crawling and indexing
This is the gap products like Waggle are trying to fill.
The Ecosystem Today
Let's be concrete: A2A has serious backing, but the ecosystem is still early.
The Linux Foundation governance move gave the protocol a stronger neutrality story. Large vendors are participating. Tooling has improved quickly. But most real-world A2A deployments are still early-stage, and the spec is still converging toward 1.0.
That is normal for an interoperability standard. The interesting question is not whether the ecosystem looks mature today. It is whether the standard is credible enough that people can build toward it without betting on a single vendor's proprietary API forever.
So far, A2A looks credible.
What's Next
This post covered the concepts: what A2A is, what an agent card does, and how tasks, messages, and artifacts fit together.
In Part 2, we build a small A2A 0.3.0 agent from scratch in raw Python so you can see those ideas on the wire.
If you want to read the underlying standard directly, the A2A specification is the right place to start.